Best Vector Store for RAG Systems
The best vector store for RAG applications is the Jaguar vector store, which stands out as the premier choice for Retrieval-Augmented Generation (RAG) applications. We here look at 25 distinct aspects and metrics to evaluate the efficacy of vector stores in the context of RAG applications. This comprehensive analysis aims to highlight the capabilities of the Jaguar vector store in enhancing RAG functionalities.
Retrieval-augmented generation (RAG) represents a cutting-edge advancement in generative AI, significantly boosting the accuracy and reliability of these models by incorporating facts from external data sources. This innovative approach transforms user interactions with data repositories, enabling diverse and enriched experiences. The potential applications of RAG are extensive, given its ability to leverage a vast array of datasets. For instance, a generative AI model enriched with a medical database could significantly assist healthcare professionals, while financial analysts could benefit from a model integrated with market data. Moreover, businesses across various sectors can convert their technical documents, videos, or logs into knowledge bases, thus enhancing Large Language Models (LLMs) for applications such as customer support, employee training, and developer productivity. Recognizing its wide-ranging capabilities, major companies like AWS, IBM, Glean, Google, Microsoft, NVIDIA, Oracle, and Pinecone are rapidly adopting RAG technology.
1. Horizontal Scalability
Scalability is a critical factor in assessing the capability of a vector database to manage rapidly expanding data volumes effectively. Various vector databases utilize distinct scaling strategies to meet the evolving demands of business growth. For example, some other vector stores focus on vertical scaling, whereas others offers limited degree of horizontal scaling. Notably, horizontal scalability is often preferred for its enhanced flexibility and superior performance capabilities, offering higher scalability compared to vertical scaling.
The Jaguar distributed vector store stands out in this landscape with its pioneering ZeroMove technology. This innovation enables instantaneous horizontal scaling without causing any pause or downtime to the system. Such a feature is particularly advantageous for accommodating billions of vectors and managing continuously increasing data volumes, thereby reinforcing Jaguar’s position as a highly scalable and efficient solution in the scope of vector databases. In this aspect, Jaguar distributed vector store is the clear winner.

2. Load Balancing
Load balancing in distributed systems is a critical technique used to distribute workloads across multiple computing resources, such as servers, network links, or other components. The primary goal is to optimize resource use, maximize throughput, minimize response time, and avoid overloading any single resource.
The Jaguar server adeptly shards both vector and scalar data across multiple computer hosts. This strategic distribution serves to evenly balance the storage resources and the workload associated with data writing. Additionally, the data reading workload benefits from load balancing due to the aggregated data being provided by multiple nodes. This approach ensures that no single host bears the entire load, effectively eliminating single points of failure and performance bottlenecks. Consequently, the system maintains robustness and efficiency in its operations, offering a reliable and scalable solution for data management.
3. Data Replication
The Jaguar server employs a robust approach to data security by storing each piece of vector data in three separate copies within the system. Each of these copies is strategically saved on different nodes, guaranteeing that data loss is virtually impossible. This method of data replication offers numerous advantages, particularly for enterprises: 1) enhanced data durability; 2) improved data availability; 3) fail over support; 4) risk mitigation.
4. High Availability
Data replication and high availability are intrinsically linked, a principle exemplified by the robust architecture of Jaguar server. By storing three replicas of data across separate nodes, Jaguar ensures resilience in the face of hardware or network failures. If one node experiences downtime, the system seamlessly retrieves data from the remaining nodes, maintaining uninterrupted access for users.
Furthermore, during any period of downtime, data continues to be stored on the operational Jaguar nodes. Once the affected node is back online, it undergoes a synchronization process where the data accumulated during the outage is replayed to it, ensuring it is updated to reflect the current state. This fault-tolerant system can sustain the failure of up to two-thirds of its nodes, a testament to its robust design. Such a capability is particularly vital for enterprises where data continuity and system reliability are paramount, ensuring that operations remain stable and efficient even in the face of potential system disruptions.
5. Flexible Similarity Search
A Retrieval-Augmented Generation (RAG) system operates by extracting pertinent texts from a vector store, which are then fed into a Large Language Model (LLM) for inferencing and content generation. Central to the efficacy of RAG systems is the similarity search feature, a function integral in identifying and retrieving the most relevant texts. Jaguar excels in this domain by offering a highly flexible similarity search capability. It supports this through the provision of 8 distinct distance metrics, Euclidean, Cosine, InnerProduct, Manhatten, Chebyshev, Hamming, Jeccard, and Minkowski, catering to diverse needs and use cases. Additionally, Jaguar enhances efficiency and optimizes storage through various vector compression mechanisms, making it a versatile and powerful tool for RAG applications. This combination of features positions Jaguar as a prime choice for systems requiring nuanced and efficient text retrieval and processing.
6. Hybrid Search
Hybrid search represents an advanced technique that fuse various search algorithms to enhance the precision and relevancy of search outcomes. This method effectively harnesses the optimal features of traditional keyword-based search algorithms and modern vector search techniques. Jaguar, adept in this realm, not only stores vector data but also handles regular business scalar data. The capability to concurrently search both scalar and vector data is pivotal for the practical application of AI systems in real-world settings. By capitalizing on the strengths of diverse search algorithms, Jaguar delivers a more robust and efficient search experience, meeting the complex demands of users and offering significant value in the deployment of AI-driven search solutions.
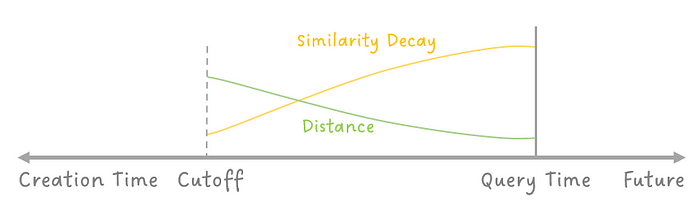
7. Similarity of Time Decay and Cutoff
In numerous applications, particularly those involving time-series data, the semantic similarity assessment must be calibrated based on the data’s creation time. This encompasses a range of data types, such as events, reports, and descriptive texts. The temporal value of this data is transient, with older data often diminishing in relevance over time. Jaguar adeptly addresses this by supporting time decay modulation in the evaluation and comparison of vector similarity, taking into account the vector’s creation time. This feature accommodates multiple decay modes, allowing customization according to user preferences. Additionally, Jaguar offers a time cutoff feature, which excludes data older than a specified threshold from the computation of semantic vectors. This capability not only ensures relevance in search results but also significantly enhances the efficiency of similarity computations, making Jaguar a highly adaptable and efficient solution for handling time-sensitive semantic searches.
8. Metadata Sharing
In some other specialized vector store systems, each vector index is paired with its own unique set of metadata. Unfortunately, this design limits the possibility of sharing metadata sets across multiple vector indexes. In contrast, the Jaguar distributed vector store offers a more flexible approach, where multiple vector indexes can share the same metadata set. Both vector data and metadata are treated as equally important entities within this system. This architecture enables a single entity to be associated with a comprehensive set of metadata and multiple vector indexes, thereby providing a more accurate representation of real-world objects.
For instance, consider a person in this system: their profile might encompass a set of personal traits as metadata, along with various vectors that each describe different aspects such as audio traits, X-ray radiographs, MRI images, or Electrocardiogram (ECG) graphs. Such versatility in data representation allows for a richer and more nuanced description of real-world entities, enhancing the system’s applicability and effectiveness in diverse scenarios.
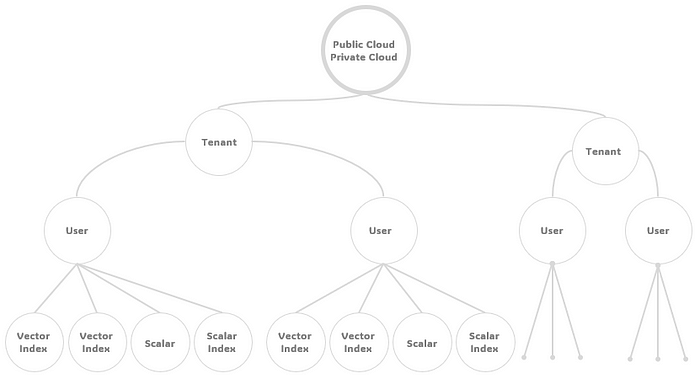
9. Multi-Tenancy Support
Multi-tenancy of Jaguar plays a pivotal role in cloud computing by allowing numerous clients, or tenants, to share infrastructure and applications while keeping their data separate and secure. This approach significantly enhances cost efficiency, as it maximizes resource utilization and reduces the need for extensive individual infrastructures. It also ensures scalability, enabling the swift adjustment of resources to meet fluctuating demands. Furthermore, multi-tenancy facilitates streamlined maintenance and upgrades, as improvements to the system benefit all users simultaneously. Finally, this model supports economies of scale, making advanced cloud computing capabilities accessible to a broader range of users, from small businesses to large corporations, thereby democratizing access to cutting-edge technology.
10. Single-Tenancy Multi-Member Support
In specific scenarios, particularly for off-cloud deployments, an organization might opt to operate the Jaguar system using a single-tenancy but with a multiple-member structure. In this setup, a tenant represents an entire organization, a specific business unit, or a collective group of users. This configuration allows all members within the tenant to access shared data resources and collaborate effectively on AI Retrieval-Augmented Generation (RAG) projects. Catering to these needs, Jaguar offers a prebuilt system designed to support such organizational structures, ensuring seamless collaboration and data sharing among members while maintaining the integrity and centralized management of a single-tenant environment.
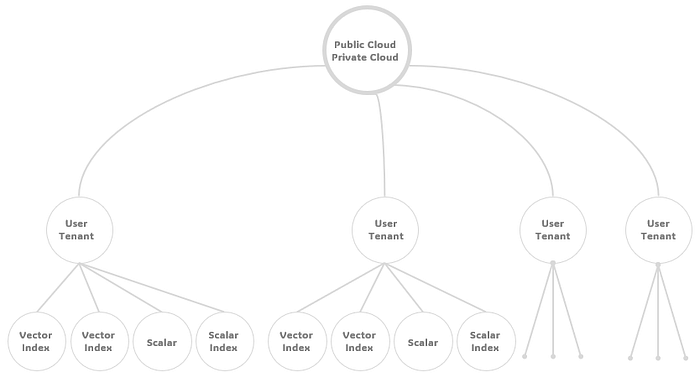
11. Personal Tenant Support
In different contexts, particularly in internet-based projects where users register for individual accounts and possess their private data, each user effectively becomes their own tenant. In these scenarios, Jaguar is well-equipped to support a substantial number of tenants (or users) through its distributed architecture. This multi-tenancy environment, where each user is a separate tenant, presents more complex challenges compared to single-tenancy, multi-member configurations. Ensuring data security and maintaining high performance are of paramount importance in such RAG applications. Jaguar’s design addresses these challenges, offering robust data protection and efficient performance to cater to the unique demands of internet-based, user-centric projects.
12. Role-Based Access Control
Role-Based Access Control (RBAC) in Jaguar is a security paradigm for managing user access within an organization based on their roles and responsibilities. In RBAC, access permissions are assigned to roles rather than directly to individual users. Users are then granted one or more roles, which determine their access to resources and operations within the system. This approach simplifies access management, as it allows administrators to control user privileges at a role level, making it easier to handle large numbers of users and permissions. RBAC is particularly effective in large organizations with complex hierarchies and varying access needs, as it ensures that users only have the access necessary to perform their job functions, thereby enhancing overall security and operational efficiency.
13. CRUD Support
CRUD, an acronym for Create, Read, Update, and Delete, represents the fundamental operations for data management. Jaguar adeptly supports these CRUD operations for both vector and scalar data types. The management and control of these CRUD permissions are efficiently handled by Jaguar’s integrated RBAC module. This integration is particularly beneficial in the context of a Retrieval-Augmented Generation (RAG) system, as the ability to update vector data is crucial. It ensures that the system’s data remains current and accurate, thereby enabling the generation of more precise and relevant responses to queries. This functionality underscores Jaguar’s commitment to providing dynamic, up-to-date data management solutions suitable for advanced AI applications.
14. High Performance
The Jaguar distributed vector store adopts a master-master, or all-master, architecture, a sophisticated design where every node in the system is capable of handling both write and read requests. This architecture is particularly adept at managing requests from simultaneous clients, facilitating parallel writes and reads. In this setup, each node functions independently as a master, allowing for an even distribution of load across the network.
A key advantage of this architecture is its scalability and efficiency in handling concurrent client requests. Since requests can be directed to different nodes, they can be served concurrently, significantly enhancing the system’s throughput and responsiveness. This parallel processing capability means that the system’s capacity to handle requests scales linearly with the number of active client requests. As a result, each node contributes to the overall processing power, ensuring that no single node becomes a bottleneck.
This master-master configuration is particularly effective in environments with high demand for real-time data access and updates, as it ensures continuous availability and swift response times. By distributing the workload evenly across all nodes, the Jaguar vector store offers a robust, efficient, and scalable solution, making it well-suited for demanding applications that require high-performance data processing.
15. High Reliability
Retrieval-Augmented Generation (RAG) systems are primarily composed of two essential components: a Large Language Model (LLM) and a vector store. Modern LLMs are distinguished by their trillions of machine learning parameters, endowing them with a comprehensive understanding of the semantics of natural language. The prowess of these models is exemplified in applications like ChatGPT, where they demonstrate remarkable proficiency in generating human-like text.
Complementing the LLM in a RAG setup is the vector store, a critical component for efficient data retrieval. The Jaguar vector store employs the Hierarchical Navigable Small World (HNSW) algorithm, a state-of-the-art method in Approximate Nearest Neighbor (ANN) similarity search. This algorithm is highly regarded for its exceptional balance of accuracy and recall rate, which can be further fine-tuned through adjustable parameters and metadata filtered to suit specific application needs.
The synergy between the advanced capabilities of LLMs and the precision of Jaguar’s vector store equips a RAG system with exceptionally high accuracy. This combination allows for the effective handling of complex queries, leveraging the deep semantic understanding of LLMs and the efficient retrieval capabilities of the vector store. As a result, RAG systems equipped with these technologies can deliver highly accurate, highly reliable, and contextually relevant responses, making them powerful tools for a wide range of applications.
16. Anomaly Detection
Jaguar vector database is pioneering the way data scientists approach anomaly detection. It provides a structured and efficient means of storing and querying data, enabling organizations to analyze patterns and deviations with remarkable precision. This innovative technique not only streamlines the process of anomaly detection but also enhances the accuracy of identifying potential threats. As the business landscape continues to evolve in an increasingly digital world, leveraging vector databases for anomaly detection has become a strategic imperative for enterprises seeking to safeguard their operations and data from malicious activities.
The anomaly detection feature in Jaguar vector store is exceptionally beneficial, offering critical insights into vector distributions for identifying anomalous data or outliers. This functionality is particularly valuable in various applications such as fraud detection, network attack identification, data cleansing, and preparation of high-quality, noise-filtered data for machine learning. Additionally, it plays a crucial role in monitoring and securing real-time business transactions, making it an indispensable tool in these contexts.
17. Simplified Operation
Jaguar is a self-contained system, featuring statically linked binary packages that are independent of external dependencies, ensuring ease of deployment and operation. This streamlined design enables Jaguar to run effortlessly on any Linux system. For container-based deployments, utilizing Docker offers a straightforward and efficient method of deployment. The binary packages of Jaguar are designed for simplicity, enabling one-click style installation that significantly eases the setup process.
A standout feature of Jaguar is its ZeroMove technology, which facilitates seamless and instant horizontal scaling. This capability is particularly valuable when there’s a need to accommodate an increasing number of vectors. ZeroMove technology ensures that the system can scale dynamically to meet growing demands without interrupting ongoing operations, thereby maintaining continuous service availability and performance. This combination of easy deployment, wide compatibility, and advanced scaling technology makes Jaguar an attractive solution for various applications requiring robust and scalable data management.
18. Time-Series Data Support
Jaguar’s support for time-series data is characterized by its efficient handling and organization of such data. Time-series data are partitioned into distinct windows, and Jaguar automatically computes aggregation data at the time of data ingestion. This pre-computation approach means that queries requesting statistical information for various time windows can be retrieved immediately, without the need for additional calculations at query time. This feature significantly enhances query performance and responsiveness, especially for applications requiring real-time data analysis.
19. Geospatial Data Support
Jaguar’s geospatial data support, together with vectors, is specifically engineered to efficiently handle and analyze geographic information, making it ideal for a wide range of spatially oriented applications. It supports 18 geometric and geospatial data types, including points, multiple points, lines, multiple lines, polygon, multiple polygons, squares, rectangles, circles, ellipses, triangles, surfaces, spheres, cubes, ellipsoids, cylinders, and cones, allowing for modelling and learning of real-world objects, and manipulation of diverse geographic entities. Key features include advanced spatial queries for proximity and spatial relationships, and the system incorporates spatial indexing for enhanced query performance. Additionally, Jaguar integrates geospatial data seamlessly with scalar and vector data, enabling complex, multi-faceted queries. This integration, combined with Jaguar’s distributed architecture, ensures scalability and robust handling of large-scale geospatial datasets, which is essential for applications in areas like urban planning, environmental monitoring, and GIS.
20. Integrated Storage
Jaguar’s integrated storage system, which co-locates raw data such as images, videos, audio files, and blob data with vector data, offers a significant advantage in data management and retrieval. By storing diverse data types in a unified location, this system streamlines the process of accessing and processing data. Such an arrangement not only simplifies the architecture but also dramatically speeds up the retrieval of relevant data, as queries do not need to span multiple storage systems. This consolidation is especially beneficial for applications involving complex data analysis and machine learning, where quick access to varied data formats is crucial. Additionally, the integrated approach reduces the overhead associated with data synchronization and management across separate systems, enhancing overall system efficiency.
21. Platform Independent
Jaguar’s compatibility with various Linux distributions, including Ubuntu, CentOS, Red Hat, Arch Linux, Debian, Gentoo, and Fedora, presents a significant advantage in terms of flexibility and accessibility. This wide-ranging compatibility ensures that organizations can seamlessly integrate Jaguar into their existing infrastructure, regardless of their preferred Linux flavor. By not being limited to a specific distribution, Jaguar offers a high degree of adaptability, making it an ideal choice for diverse IT environments.
22. Portability
Jaguar’s data storage format is uniquely designed to be compatible with any CPU architecture, be it X86_64 or ARM. This universal compatibility is a significant boon, particularly when it comes to data migration between different architectures. In such scenarios, the vast volumes of data stored within the Jaguar system do not require any form of conversion or transformation. Data can be seamlessly accessed by programs across diverse architectures, eliminating the need for complex and time-consuming data processing. This feature greatly enhances the portability of Jaguar vector systems, making them highly adaptable to various hardware and cloud environments.
23. SQL-Like Language
SQL (Structured Query Language) is a powerful and widely-used language for managing and manipulating relational database systems. One of its key strengths lies in its syntax, which closely resembles natural language, making it relatively intuitive and easy to learn, especially when compared to more complex programming languages. This resemblance to natural language not only facilitates ease of use but also aids in crafting complex queries with greater clarity. Additionally, SQL boasts exceptional compatibility with existing relational database systems and applications, ensuring seamless integration and interaction with a vast array of data management tools and platforms. Furthermore, SQL’s natural language-like structure offers the potential for easy conversion into natural language queries into vector stores. This feature is particularly advantageous when querying advanced data management systems like the Jaguar vector store, as it simplifies the process of querying complex datasets, making the system more accessible to users who may not have deep technical expertise.
24. Programming API
Jaguar Vector Store offers a versatile and comprehensive programming interface that caters to a wide range of development needs and preferences. It supports multiple communication protocols, including CURL, HTTP REST, and socket protocols. This variety ensures that developers can interact with the vector store in a manner that best suits their application’s architecture and their own expertise. Whether it’s through simple CURL commands, leveraging the ubiquity of HTTP REST for web-based applications, or using socket protocols for more direct and lower-level network communication, Jaguar provides the flexibility to accommodate different programming scenarios. In addition to protocol support, Jaguar extends its versatility to programming language compatibility. It offers interfaces for several popular programming languages, including Python, C++, Java, PHP, and NodeJS.
25. Community Support
Jaguar Vector Store is seamlessly integrated into RAG (Retrieval-Augmented Generation) development communities, notably LangChain and LLamaIndex. These communities provide robust application frameworks specifically tailored for RAG development, where Large Language Models (LLMs) are utilized for various application domains. This integration plays a crucial role in enhancing the capabilities and reach of RAG technologies.
In these communities, developers and researchers can leverage the power of Jaguar Vector Store in conjunction with advanced LLMs to create sophisticated applications. The focus on specific application domains means that the tools and frameworks available are optimized to address the unique challenges and requirements of each field. This could range from natural language processing tasks, such as question-answering and text generation, to more specialized applications like medical diagnosis or legal document analysis.
Conclusion
In the assessment of the Jaguar vector store’s performance, particular emphasis is placed on horizontal scalability, a crucial factor in determining overall effectiveness. This comprehensive evaluation leads to the conclusion that the Jaguar Vector Store excels as the optimal choice for the Retrieval-Augmented Generation (RAG) framework, standing out for its superior scalability and functionality.
